# Linked Data: The role of the Data Server
So I have talked about how RDF is really simple, and why Linked Data are the roots of the web… but we need a way of serving this data in a meaningful way, this is where the Data Server steps in!
The allegory continues……
Here we see our home-grower digging up some potatoes.
The potatoes are Linked Data Objects (with relations interconnecting them), the home-grower is our data server and the act of digging is the process of fetching information (via a method such as REST). The soil is the machine-friendly Data Web.
Because the potatoes cannot be eaten straight from the ground:
The home-grower will need to prepare the potatoes by peeling, chopping and then cooking them. They may be cooked by boiling, baking or using some other method.
The home-grower is still a data server, and the act of preparing and cooking is to be able to get the data in a certain context with other information that the user demands, different users will want to see things in different ways hence the different cooking methods. Context is essential.
The potatoes are then ready to serve:

Because different people will like to eat their potatoes in different ways and with different things the home-grower will know exactly how their guests would like their potatoes! Some people like quorn fillets with peas and mashed potato and some prefer a lump of meat with some roast potatoes.
Different people are essentially different users, and they will want to see the data in a human friendly fashion. So styling and interaction is a part of serving this information. Note that presentation is related to the type of data that you want to show, but it should not be the same thing, a good use of data-code-presentation separation is advised when developing systems.
OpenLink Virtuoso: The Linked Data Server
Virtuoso is a “Universal Server”, which means that it is capable of doing all that is described above. To break things down a bit:
- Being able to fetch information from data stores via webservices (and via scraping/sponging)
- Being able to manipulate Linked Data graphs.
- Storing its own graphs inside the native database (or other database management systems via virtualisation techniques).
- Using query languages (e.g. SPARQL) to find specific data.
- Using methods of graph manipulation to provide data in a certain context.
- Providing meaningful data to the user using the typical XHTML+JavaScript+CSS setup.
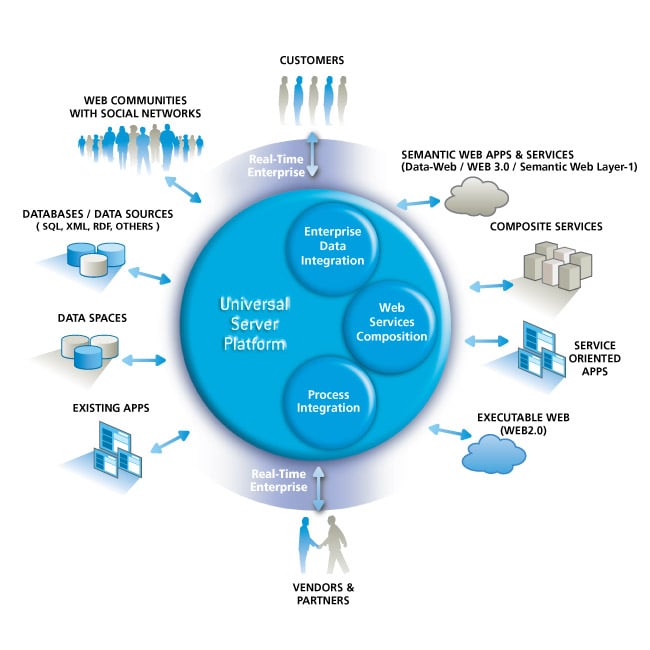
Image is a conceptual view of the Virtuoso architecture and is available, with more information, from the Virtuoso homepage
More information
More information is available from the following Document Web sites:
- The Virtuoso Homepage, the OpenLink Whitepapers and the Virtuoso Documentation system
- Wikipedia sites for the subjects of Object’s in computer science (DBpedia: Object (computer science) ) and Web 3.0 (DBpedia: Web 3.0)
- Data Servers are essentially extended triplestores; you may be interested in seeing the Wikipedia article for triplestores (DBpedia: triplestore). (As OpenLink Virtuoso is omnifunctional in nature, the triplestore is just one part of this powerful architecture)
p.s. sorry about the crude drawings, but they do show the point. Once again if you would like to use them somewhere then do give me a nudge, I am very unlikely to say no but I would like you to tell me about it first. Thank you ![]()
p.s. do email me, skype me or comment if you would like me to clear anything up, or if you would like to discuss how Virtuoso might work for you. My details are available on my personal site and via my personal URI.

April 27th, 2008 at 10:54 pm
Lucid (amusing!) drawings to communicate a complex subject. Reminds me of what Hitachi a few years ago did to explain their perpendicular storage tech for hard drives.
April 30th, 2008 at 11:25 am
[...] “Linked Data: The role of the data server“ [...]