Now for an incredibly Formal Blog Post. For equality I thought that I should open this up to as many people as possible, I’ve been pondering about making this blog post for a while, and I have even discussed the project with a few of you. Receiving my introduction pack and registration guide this morning has prompted me to write this post.
Intro
Many of you know that, I will be starting postgraduate study at the University of Bristol from the end of this September (2008). This will be a one-year full-time MSc course with project, the subject area is “Machine Learning and Data Mining“.
I would like to open up my project idea to an organisation in return for sponsorship of the course. I only ask for the cost of the tuition (£3950 GBP, which is currently roughly $7711 USD / €4982 Euros / $8032 Canadian Dollars / $8428 Australian Dollars / 323385 Indian Rupees / 830725 Japanese Yen / 52861 Chinese Yuan / 8102 Swiss Francs). In return the sponsor would have some say in the project itself, in addition to logos and names on all relevant websites and in documentation (negotiable).
I would (potentially) be interested in taking the project further after the project has been completed, this could be in the form of a business idea or another academic project. This is also negotiable.
My Project Proposal
I do already have an idea for a project, and have even written a project proposal which has been approved by the department. However, the content of that project proposal is negotiable and I could even change it completely depending on my interests/skills, the criteria for approval and also the sponsors interests.
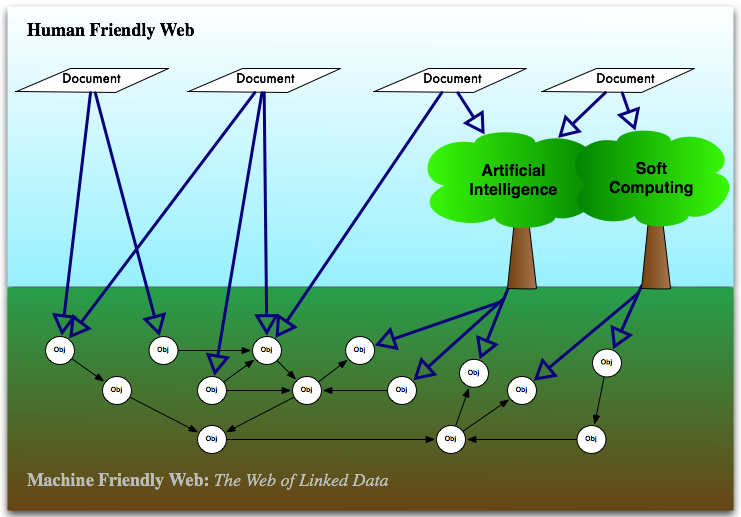
The idea I already have will be an entirely new way of turning Free-Text into Linked Data, with the specific use-cases being very humanities (including anthropology and religion) based. But as said before, this is negotiable.
Course Information
The postgraduate course is officially titled “MSc in Advanced Computing (Machine Learning and Data Mining)”, it is a taught course but contains a full academic project. Topics within the course include Logic Programming (using Prolog), Bayesian methods, Natural Language Processing, Genetic Algorithms/programming, Neural Networks, Fuzzy Logic, Reinforcement Learning and some Bioinformatics content.
The official programming languages used at the University of Bristol include: C, Java, Haskell, Prolog, Progol… etc
Systems/Frameworks include: Weka, MatLab
A little about me
If you have just stumbled across this blog post, then you’ll be wondering about who I am. So a brief biographical summary:
I currently work as a Technology Evangelist for OpenLink Software dealing with Semantic Web/Linked Data technologies in addition to data portability, social web and database technologies. In May 2007 I completed my undergraduate degree with a 2:1 honours and a Double A grade for my final year project titled “Adding Semantics to Social Web Tagging Systems”, the undergraduate degree was a “BSc(Hons) in Intelligent Systems and Software Engineering” at Oxford Brookes University. My computer science interests are in the “Evolution of the Web” (so Semantic Web/Linked Data, the Social Web, Web 3.0, WUPnP and the Intelligent Web), Open Source Software and Open Data, Programming Languages and finally Intelligent Systems (mainly Logic Programming, Machine Learning, Data Mining, Agent Technology and Knowledge-Bases). I have experience in many programming/query languages, but some of my favourites include: Ruby, Java, Haskell, Prolog and SPARQL. My interests outside of computer science include: psychology, philosophy, music, religion and esoterica. I am a “Liberal Catholic Anglican” Christian and active/open-to/passionate-for Interfaith/Interreligious dialogue. I am a full member of the British Computer Society (BCS) and the Association of Computing Machinery (ACM). There is more about me on my simple homesite, my blog and my linkedin account, other information (including a CV) can be provided on request.
Important Dates
- Autumn Term: Monday 29th September 2008 to Friday 12th December 2008
- Spring Term: Friday 9th January 2009 to Friday 20th March 2009
- Summer Term: Monday 20th April 2009 to Friday 19th June 2009
I must have details about sponsorship as soon as possible, the final date for setting sponsorship up is Friday 12th September 2008…. and I really don’t want to leave it until then.
Useful (Official) Links
- Machine Learning and Data Mining Unit Descriptions
- University of Bristol and the University of Bristol’s Computer Science Department
If you are interested
If you are interested then please do let me know. I’m available by email or jabber… we can converse by phone or skype… and we can even meet up in/near the wonderful city of Bristol (UK).
- Email: danieljohnlewis [-at-] gmail [-dot-] com
- Jabber/GTalk: [email protected]
- Skype: daniel.lewis
- Phone: +447834355516 (UK specific: 07834355516)
- Current Location: Clifton, Bristol, England, UK (it’s in the South-West, about a 2 hour train journey from London)
- Current Time Zone: British Summer Time (GMT+1)
I will announce
I will announce on my blog when I receive funding. So if you don’t hear, then please do assume that I have not found any yet.
Many many thanks for reading, and I hope to hear from interested people soon.
Cheers,
Daniel