# Linked Data are the roots for the Future Web
OK, so in my last post (“RDF: Simpler if you look at it in a different way“) I said that RDF is a modeling framework to link data together in the form of object to object relationships, I briefly mentioned some “vocabularies” (aka ontologies) and some formats (e.g. Notation3, RDF/XML). I want to mention again that it is a modeling framework for Linking Data, and not specifically a format for importing and exporting (although it can be used in this way).
This brings me on to the topic of Linked Data. A lot of people, some of which are part of the W3C, want to see a “Web of Data” where data is linked across domains (physical (e.g. web servers), virtual/symbolic (e.g. knowledge bases or domains of knowledge/understanding)). This is where every “thing” on the web is structured in a kind of “object orientated” way, RDF happens to be a standardised way of achieving this. But this does not mean that a “Web of Data” will replace the document view that we see today, it means that the Linked Data are the roots and a human view is what the user sees:
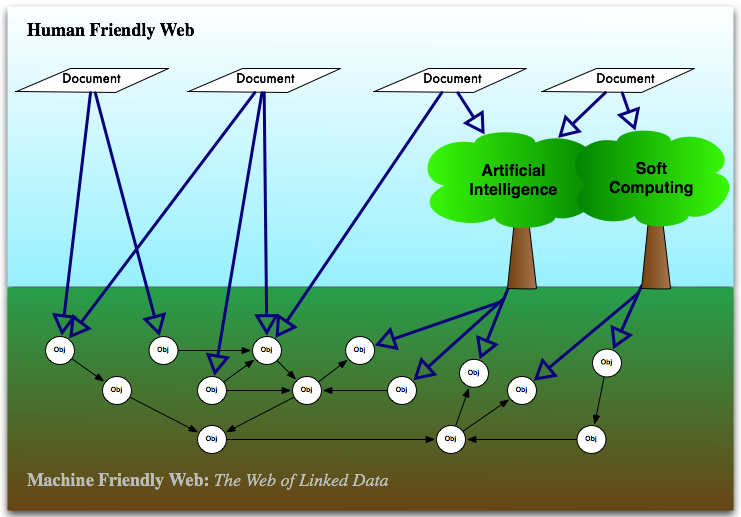
Figure: Linked Data are the roots for the future web (black arrows are “labeled arcs” aka “relationships”/”predicates”)
Here we see documents rendering information from objects which are in the enriched soil, this is so that the humans can consume the information. You can’t eat potatoes raw, you’ll find it hard to digest! With information in this form your data is more meaningful as it shows idiosyncrasies with other data via labeled links. Note that the documents are able to do this either through getting information directly from a graph, or by querying using a language called SPARQL.
We also see the two trees of Artificial Intelligence and Soft Computing. They will also want to get at the lovely nutrients in the soil. These trees transform nutrients into fruit, and fruit is edible by humans. In reality these trees are intelligent software agents (either server or client side), capable of inferring new information and dealing with uncertainty.
These meaningful objects all have their own identifier in the form of a URI, which should be an HTTP accessible URI. A URI in this form is the name and the co-ordinates of that particular object. HTTP URIs can be used within RDF to form Linked Data. There is a lot of Linked Data out there already which is open and ready to use (see Richard Cyganiak’s Linked Open Data Cloud for the data sets that the Semantic Web Interest Group / Linked Data Group are aware of), so its just a case of getting your data out there and using it… and thats how we make it real!
More information
More information is available from (in Human Friendly form):
- The Linked Data Group and the Linking Open Data Wiki
- “Design Issues - Linked Data” by Tim Berners-Lee
- “Teaching triples to a six year old” by Leigh Dodds
- Some Linked Data systems: DBpedia (“DBpedia Mobile” now available on mobile/cell phones via a map mashup), Umbel, Musicbrainz, Geonames and many more in the linked data cloud.
- “Linked Data Deployment” at XTech 2008 by me (slides and paper coming soon!)
- “Linked Data Spaces and Data Portability (PDF)” by Kingsley Idehen and Orri Erling at LDOW2008@WWW2008.
- Other papers and presentations at LDOW2008.
- “Linked Data Principles Revisted” by Michael Hausenblas on the O’Reilly XML Blog
Theres a lot out there, not only academic stuff but business stuff too. Explore, and if you find anything interesting then please do share it here!
Thanks for reading,
Daniel

April 27th, 2008 at 10:47 pm
[...] 27th, 2008 by daniel So I have talked about how RDF is really simple, and why Linked Data are the roots of the web… but we need a way of serving this data in a meaningful way, this is where the Data Server [...]
April 30th, 2008 at 11:21 am
[...] “Linked Data are the roots of the Future Web“ [...]