# RDF: Simpler if you look at it in a different way
I have figured out why some people are reluctant to use RDF, and its because they are seeing it as a format and not a model. RDF is a modeling framework, it is not a format!
RDF is supposed to be understood in a visual way:

Which is essentially understood as a triple of URIs:
<https://myopenlink.net/dataspace/person/danieljohnlewis#this> <https://xmlns.com/foaf/0.1/made><https://uk.youtube.com/watch?v=oWfaoP1Ti2Q>
And this is basically in a format called n3 (Notation3), another option would be to have it in XML format, but that is very complex to understand (but good for machine reading).
There is generally a way to start implementing your data as RDF:
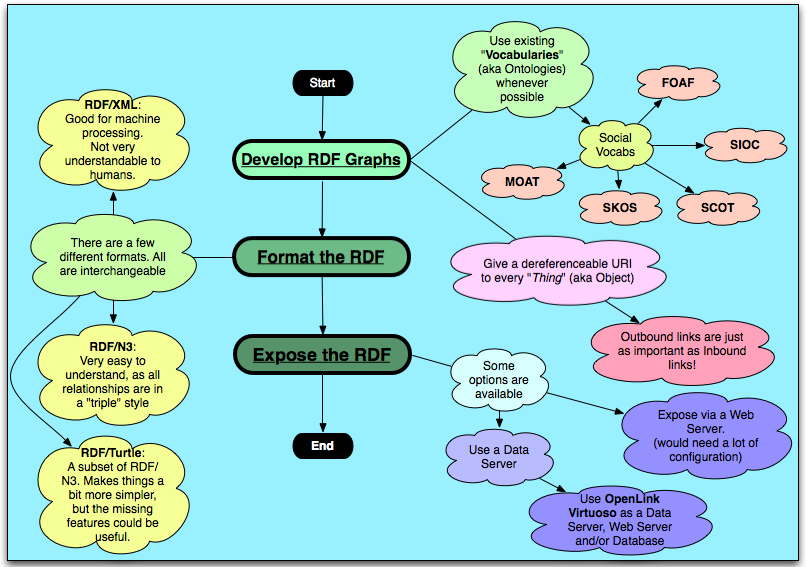
This really highlights the fact that RDF is not a format, but a model for Data. You model your data in a graphical way and then you choose which format:
- Visualise your data as a set of atomic objects and relationships between them, this is your RDF.
- There are ontologies available, such as FOAF and SIOC which are suited for Social Networking applications.
- Linking out is as important as linking in, a link out will provide more meaning to that data that it is linking from. For example I could say that https://myopenlink.net/dataspace/person/danieljohnlewis#this (<- the “Subject”) owl:sameAs (<- the “Predicate”/”Relation”) https://www.facebook.com/people/Daniel_Lewis/277003772 (<- the “Object”). A Semantic Web application would then be able to work out that danieljohnlewis on myopenlink is the same person as 277003772 on Facebook. (This is where the notion of Linked Data comes in)
- Format your RDF data
- There are a few options. Generally RDF/N3 is suggested for developers who are exploring the Semantic Web, as it is simply a list of URIs. RDF/XML is not suggested for the beginner, as it adds in all of the complexities of XML which don’t really fit in with the simplicity of a triple graph…. but RDF/XML is quite good for machine reading. Generally the format doesn’t matter as they are all interchangeable. Another option is RDF/Turtle.
- Expose your data
- I highly recommend using a Data Server. OpenLink Virtuoso is a very good option as it is fast and reliable, and you can use it as a Data Server, a Web Server and/or a Database Server… it supports SQL and RDF too.
More information
More information is available at these Document Websites:
- Getting into the Semantic Web and RDF using N3 by Tim Berners-Lee
- Notation 3 (Introduction) by Tim Berners-Lee
- RDF/Turtle by Dave Beckett
- Frequently Asked Questions about the Semantic Web, by the W3C
- Homepages for: FOAF (Friend of a Friend), SIOC (Semantically Interlinked Online Communities), SKOS (Simple Knowledge Organisation System), SCOT (Social-Semantic Cloud of Tags) and MOAT (Meaning Of A Tag). Which are all ontologies (aka “Meaningful Schemas” or “Vocabularies”) to fit your data into.
- The Linked Data Starting Point and the Linked Data (Introduction) article by Tim Berners-Lee
- OpenLink Virtuoso homepage, the OpenLink Virtuoso Wikipedia page and the Linked Data Deployment Technical Whitepaper (PDF).
- The Linked Open Data Cloud by Richard Cyganiak <- useful for finding out which data sets you might want to link your data to.
- My recent post about “the divide between business and academia“, “Education in the Linked Data Age” and “the Universe of Discourse” may also be useful.
(All images made by me by the way, please do get my permission before using them elsewhere)

April 23rd, 2008 at 3:05 pm
But as a model, how useful is it really? We have lots of technologies built on RDF, but little demonstration of the utility of those dependent technologies. Can we see an argument for RDF for the non-technical end-user?
I’ve found myself agreeing with sbp’s feelings towards the big-S-big-W Semantic Web. I feel like the community is turning into a load of latter-day Leibniz’s trying to eradicate vast swathes of human-level meaning as being ‘imprecise’ and ‘undesirable’. I strongly believe that the model of RDF is too simple, not too complicated, and fails to capture the meanings important to humans. In the end, aren’t they who we write our software for?
April 23rd, 2008 at 3:10 pm
Hi Joe.
My point that it is not “too complicated” and it is a lot simpler than people imagine…. plus I have actually heard people say that it is “too complicated”. Developers get stuck because the first thing they see when they come to the Semantic Web is RDF/XML… which is a real pain for humans to understand… N3 is a better option.
Plus I am not restricting this to RDF, because once people start using RDF… then people would start becoming more and more interested in OWL. Its a case of one-step-at-a-time is a lot friendlier than jumping in to the rather scary full descriptions logic boat. I am sure that you must agree.
Many thanks for your comment.
Daniel
April 23rd, 2008 at 3:18 pm
Well, I don’t agree with the Description Logic approach either. We have this formalism based upon arcs, and then we choose a logical representation which is fairly fragile and based on nodes? Plus, it uses a semantics which implicitly assumes total knowledge and infinite resources. I think that is a blind alley personally, which is why I’ve developed LOAN (https://code.google.com/p/open-nars/wiki/LOANForNarseseUsers) as a friendlier representation of Non-Axiomatic Logic. My current researches are based on using NAL to talk about Web resources. My personal approach would be to warn people away from the Semantic Web stack, and just make them more aware of the inherent semantics of their communications.
April 23rd, 2008 at 3:27 pm
Great explanation! For us designers and visionaries, it is helpful and valuable when concepts and/or technologies that should form the backbone of the Internet are communicated in a manner that is both compelling and comprehensible. gonumber.com is based on RDF and a future release of the directory will help the every day person grasp the concept through real world applications - specifically, some APIs.
April 23rd, 2008 at 3:28 pm
Hello again Joe,
The thing with RDF is that it is very widely supported, and does work. Yes there might be problems with how people use it meaning that its not entirely inferenceable but it works as a simple object description language which can be extended in the future.
I certainly don’t think that we should be steering people away from the Semantic Web stack. Just look at all of the wonderful data sets that we have available, and we can query the Linked Data web to find exactly what we are looking for. LOAN is certainly an interesting representation and I am sure that it would be good in conjunction with RDF.
Plus I am not saying that RDF is the start the middle and the end but its something we can use now, and have the tools to manipulate, remix, view and play.
Lets get people understanding the RDF graph model first.
Cheers,
Daniel
April 23rd, 2008 at 4:26 pm
I have just had a comment via skype saying that RDF is more than just social networks, and this is true. In this article I am using social networking applications as a modern-day example as the current web is very socially orientated.
RDF is adaptable, so you can have RDF describing any data objects that you may have. For example it could be biological data, it could be sports data, it could be news data. This is where the Web 2.0 starts to turn into Web 3.0.
April 23rd, 2008 at 8:15 pm
I think of RDF as “the simplest thing that could possibly work”. Whether it actually will work, is still somewhat of an open question, but I’m betting a lot on that it will.
Depending on my audience, I tend to explain RDF first in terms of a link between documents, that’s two URIs, but the meaning of the link is undefined. Then, you introduce a third URI to define that meaning. Then, you say that those URIs can identify not only documents but also physical things and abstract concepts. I think people get it when I explain it that way.
Anyway, I think we fall a bit short on creating real useful applications that can be done right now. There are many cool things that can be done right now, but we’re getting too focused on the lower level stuff and customer demands. I’m no exception, of course.
April 23rd, 2008 at 9:05 pm
Good post, and explains it pretty well. It also made me remember a post by Leigh Dodds some time ago - the framework at its core is the triple and its simplicity is what makes it so powerful for describing things. And that really is what it’s all about.
April 25th, 2008 at 11:41 am
[...] 25th, 2008 by daniel OK, so in my last post (”RDF: Simpler if you look at it in a different way“) I said that RDF is a modeling framework to link data together in the form of object to [...]
April 27th, 2008 at 10:46 pm
[...] 27th, 2008 by daniel So I have talked about how RDF is really simple, and why Linked Data are the roots of the web… but we need a way of serving this data in a [...]
April 30th, 2008 at 11:18 am
[...] Web community! Anyway, I’ve already mentioned that RDF isn’t complicated at all in my Simple RDF blog post. Some of the commenter’s also explained it in their own way, and one commenter said [...]
May 2nd, 2008 at 12:48 am
You nail the fact that RDF is a model and not a format and provides some good advice on how to pragmatically approach RDF adoption (a Good Thing).
You appear to give the RDF/XML syntax more credit than it deserves… it actively obscures the power of the simple triple-based model by tucking layers of the “striped” XML in a variety of meaningless shortcuts. Go N3 all the way; it is universally more readable by a human AND NO LESS READABLE BY A MACHINE. RDF/XML does not have an advantage over N3 as you suggest.
BTW- N3 is a superset of RDF/XML, so they are not technically interchangeable.
June 29th, 2008 at 9:41 am
[...] RDF - https://www.vanirsystems.com/danielsblog/2008/04/23/rdf-simpler-if-you-look-at-it-in-a-different-way/ [...]